3rd August 2021
Messari Spotlight: Timescale Q&A with Adam Inoue
This article was originally posted on the Timescale team blog and has been modified for this post.
The wonderful team at Timescale featured Messari Software Engineer Adam Inoue in their ongoing Developer Q&A blog which recognizes developers and technologists for doing amazing things with technology – and motivating and inspiring others to do the same!
In case you missed it! We also launched our new Messari engineering blog at https://engineering.messari.io/
Check out the interview below. To learn more about Timescale, visit their website.
Timescale Community Spotlight Q&A
Messari’s Software Engineer Adam Inoue joins Timescale to share how we bring transparency to the cryptoeconomy, combining tons of data about crypto assets with real-time alerting mechanisms to give investors a holistic view of the market and ensure they never miss an important event.
Messari is a data analytics and research company on a mission to organize and contextualize information for crypto professionals. Using Messari, analysts and enterprises can analyze, research, and stay on the cutting edge of the crypto world – all while trusting the integrity of the underlying data.
This gives professionals the power to make informed decisions and take timely action. We are uniquely positioned to provide an experience that combines automated data collection (such as our quantitative asset metrics and charting tools) with qualitative research and market intelligence from a global team of analysts.
Our users range from some of the most prominent analysts, investors, and individuals in the crypto industry to top platforms like Coinbase, BitGo, Anchorage, 0x, Chainanalysis, Ledger, Compound, MakerDAO, and many more.
About the Team
I have over five years of experience as a back-end developer, in roles where I’ve primarily focused on high-throughput financial systems, financial reporting, and relational databases to support those systems.
After some COVID-related career disruptions, I started at Messari as a software engineer this past April (2021). I absolutely love it. The team is small, but growing quickly, and everyone is specialized, highly informed, and at the top of their game. (Speaking of growing quickly, we’re hiring!)
We’re still small enough to function mostly as one team. We are split into front-end and back-end development. The core of our back-end is a suite of microservices written in Golang and managed by Kubernetes, and I - along with two other engineers - “own” managing the cluster and associated services. (As an aside, another reason I love Messari: we’re a fully remote team: I’m in Hawaii, and those two colleagues are in New York and London. Culturally, we also minimize meetings, which is great because we’re so distributed, and we end up with lots of time for deep work.)
From a site reliability standpoint, my team is responsible for all of the back-end APIs that serve the live site, our public API, our real-time data ingestion, the ingestion and calculation of asset metrics, and more.
So far, I’ve mostly specialized in the ingestion of real-time market data – and that’s where TimescaleDB comes in!
About the project
Much of our website is completely free to use, but we have Pro and Enterprise tiers that provide enhanced functionality. For example, our Enterprise version includes Intel, a real-time alerting mechanism that notifies users about important events in the crypto space (e.g., forks, hacks, protocol changes, etc.) as they occur.
We collect and calculate a huge catalog of crypto-asset metrics, like price, volume, all-time cycle highs and lows, and detailed information about each currency. Handling these metrics uses a relatively low proportion of our compute resources, while real-time trade ingestion is a much more resource-intensive operation.
Our crypto price data is currently calculated based on several thousand trades per second (ingested from partners, such as Kaiko and Gemini), as well as our own on-chain integrations with The Graph. We also keep exhaustive historical data that goes as far back as the dawn of Bitcoin. (You can read more about the history of Bitcoin here.)
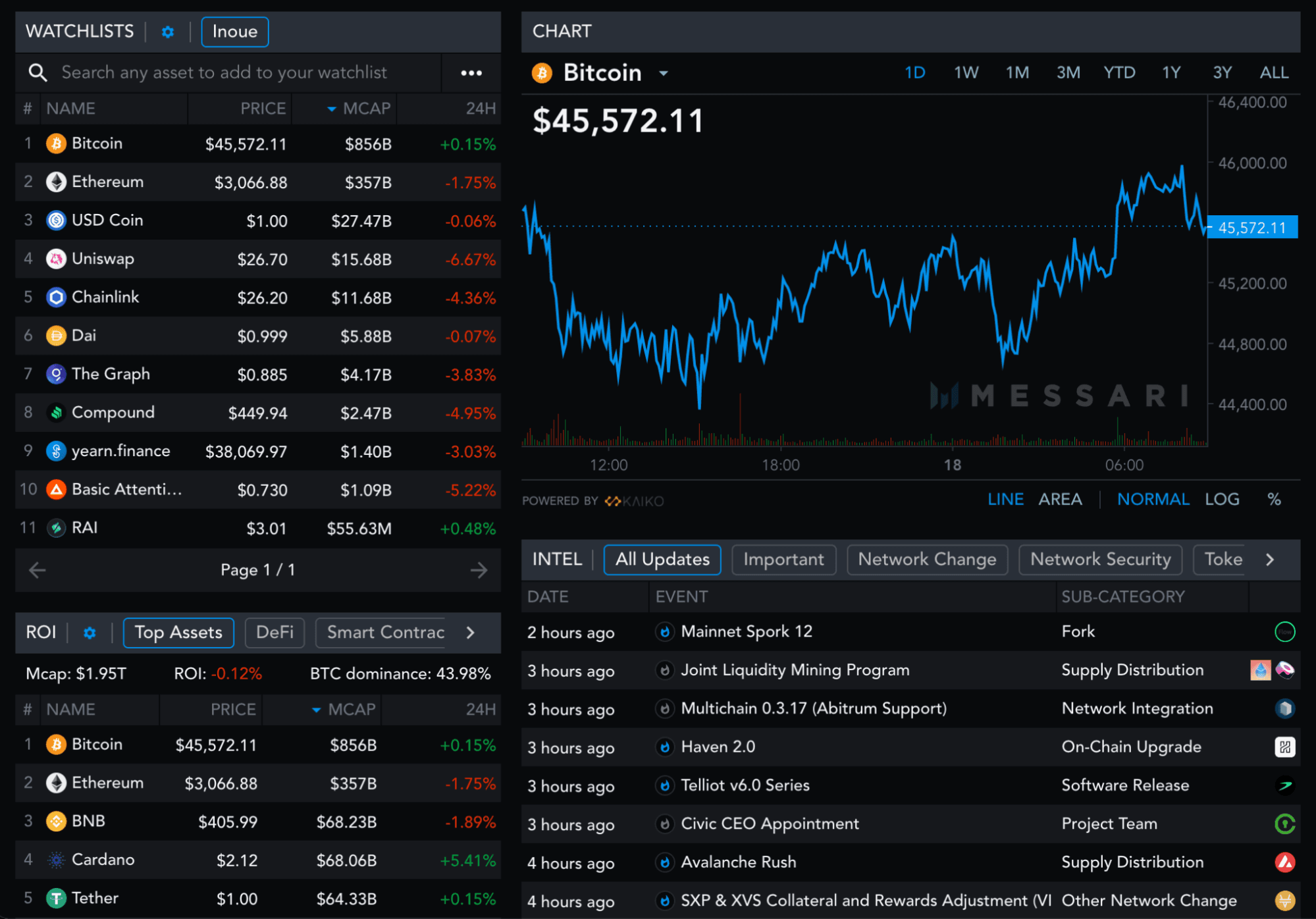
Messari dashboard, with data available at messari.io for free
Our data pipelines are the core of the quantitative portion of our product – and are therefore mission-critical. For our site to be visibly alive, the most important metric is our real-time volume-weighted average price (VWAP), although we calculate hundreds of other metrics on an hourly or daily basis. We power our real-time view through WebSocket connections to our back-end, and we keep the latest price data in memory to avoid having to make constant repeated database calls.
Everything “historical” - i.e., even as recently as five minutes ago - makes a call to our time-series endpoint. Any cache misses there will hit the database, so it’s critical that the database is highly available.
We use the price data to power the quantitative views that we display on our live site, and we also directly serve our data to API users. Much of what we display on our live site is regularly retrieved and cached by a backend-for-frontend GraphQL server, but some of it is also retrieved by HTTP calls or WebSocket connections from one or more Go microservices.

The asset view of Messari dashboard, showing various price stats for a specific currency.
The accuracy of our data is extremely important because it’s public-facing and used to help our users make decisions. And, just like the rest of the crypto space, we are also scaling quickly, both in terms of our business and the amount of data we ingest.
Choosing (and using!) TimescaleDB
We’re wrapping up a complete transition to TimescaleDB from InfluxDB. It would be reasonable to say that we used InfluxDB until it fell over; we asked it to do a huge amount of ingestion and continuous aggregation, not to mention queries around the clock, to support the myriad requests our users can make.
Over time, we pushed it enough that it became less stable, so eventually, it became clear that InfluxDB wasn’t going to scale with us. Thus, Kevin Pyc (who served as the entire back-end “team” until earlier this year) became interested in TimescaleDB as a possible alternative.
The pure PostgreSQL interface and impressive performance characteristics sold him on TimescaleDB as a good option for us.
From there, the entire tech group convened and agreed to try TimescaleDB. We were aware of its performance claims but needed to test it out for ourselves, for our exact use case. I began by reimplementing our real-time trade ingestion database adapter on TimescaleDB – and on every test, TimescaleDB blew my expectations out of the water.
The most significant aspects of our system are INSERT and SELECT performance.
- INSERTs of real-time trade data are constant, 24/7, and rarely dip below 2,000 rows per second. At peak times, they can exceed 4,500—and, of course, we expect this number to continually increase as the industry continues to grow and we see more and more trades.
- SELECT performance impacts our APIs’ response time for anything we haven’t cached; we briefly cache many of the queries needed for the live site, but less common queries end up hitting the database.
When we tested these with TimescaleDB, both of our SELECT and INSERT performance results flatly outperformed InfluxDB. In testing, even though Timescale Forge is currently only located in us-east-1 and most of our infrastructure is in an us-west region, we saw an average of ~40ms improvement in both types of queries. Plus, we could batch-insert 500 rows of data, instead of 100, with no discernible drop in execution time relative to InfluxDB.
These impressive performance benchmarks, combined with the fact that we can use Postgres with foreign key relationships to derive new datasets from our existing ones (which we weren’t able to do with InfluxDB) are key differentiators for TimescaleDB.
We are also really excited about continuous aggregates. We store our data at minute-level granularity, so any granularity of data above one minute is powered by continuous queries that feed a rollup table.
In InfluxDB-world, we had a few problems with continuous queries: they tended to lag a few minutes behind real-time ingestion, and, in our experience, continuous queries would occasionally fail to pick up a trade ingested out of order—for instance, one that’s half an hour old—and it wouldn’t be correctly accounted for in our rollup queries.
Switching these rollups to TimescaleDB continuous aggregates has been great; they’re never out of date, and we can gracefully refresh the proper time range whenever we receive an out-of-order batch of trades or are back-filling data.
At the time of writing, I’m still finalizing our continuous aggregate views—we had to refresh them all the way back to 2010! — but all of the other parts of our implementation are complete and have been stable for some time.
Current Deployment & Future Plans
As I mentioned earlier, all of the core services in our back-end are currently written in Go, and we have some projects on the periphery written in Node or Java. We don't currently need to expose TimescaleDB to any project that isn't written in Go. We use GORM for most database operations, so we connect to TimescaleDB with a gorm.DB object.
We try to use GORM conventions as much as possible; for TimescaleDB-specific operations like managing compression policies or the create_hypertable step where no GORM method exists, we write out queries literally.
For instance, we initialize our tables using repo.PrimaryDB.AutoMigrate(repo.Schema.Model), which is a GORM-specific feature, but we create new hypertables as follows:
res := repo.PrimaryDB.Table(tableName).Exec(fmt.Sprintf("SELECT create_hypertable('%s', 'time', chunk_time_interval => INTERVAL '%s');",tableName,getChunkSize(repo.Schema.MinimumInterval)))
Currently, our architecture that touches TimescaleDB looks like this:
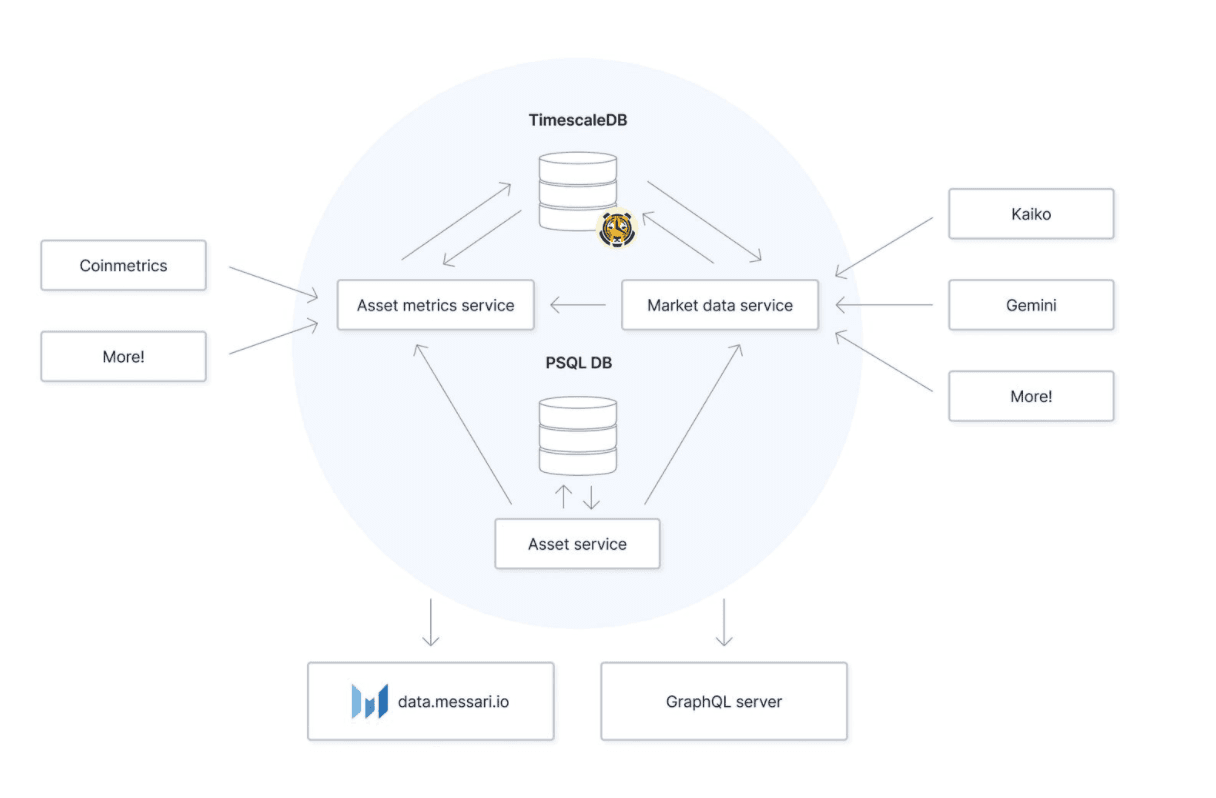
The current architecture diagram.
We use Prometheus for a subset of our monitoring, but, for our real-time ingestion engine, we’re in an advantageous position: the system’s performance is obvious just by looking at our logs.
Whenever our database upsert backlog is longer than a few thousand rows, we log that with a timestamp to easily see how large the backlog is and how quickly we can catch up.
Our backlog tends to be shorter and more stable with TimescaleDB than it was previously – and opur developer experience has improved as well.
Speaking for myself, I didn’t understand much about our InfluxDB implementation’s inner workings, but talking it through with my teammates, it seems highly customized and hard to explain from scratch. The hosted TimescaleDB implementation with Timescale Forge is much easier to understand, particularly because we can easily view the live database dashboard, complete with all our table definitions, chunks, policies, and the like.
Looking ahead, we have a lot of projects that we’re excited about! One of the big ones is that, with TimescaleDB, we’ll have a much easier time deriving metrics from multiple existing data sets.
In the past, because InfluxDB is NoSQL, linking time-series together to generate new, derived, or aggregated metrics was challenging. Now, we can use simple JOINs in one query to easily return all the data we need to derive a new metric.
Many other projects have to remain under wraps for now, but we think TimescaleDB will be a crucial part of our infrastructure for years to come, and we’re excited to scale with it.
About Timescale
Timescale is dedicated to serving developers worldwide, enabling them to build exceptional data-driven products that measure everything that matters: software applications, industrial equipment, financial markets, blockchain activity, consumer behavior, machine learning models, climate change, and more. Timescale develops TimescaleDB, the category-defining open-source relational database for time-series data, and offers fully-managed TimescaleDB and related database services. Timescale is a remote-first company with a global workforce backed by Benchmark Capital, New Enterprise Associates, Redpoint Ventures, Icon Ventures, Two Sigma Ventures, and other leading investors. For more information, join our Slack community and follow us on Twitter.
Come work with us!
If you’re a software engineer interested in helping us contextualize and categorize the world’s crypto data, we’re hiring. Check out our open engineering positions to find out more.