1st February 2023
Parallel Indexing Of Blockchain Data With Substreams
Problem:
- The increasing popularity of blockchain technology has resulted in a vast amount of data being generated daily. Interpreting and indexing this data can take time, as it is often complex and slow due to the sheer volume of information.
Goal:
- Develop a methodology for indexing contextual blockchain data with highly modular, composable, and parallel substreams.
What are substreams?
- Substreams are a powerful blockchain indexing technology developed for The Graph Network by StreamingFast. They achieve high-performance indexing through parallelization. Learn more about substreams in their documentation here!
Methodology:
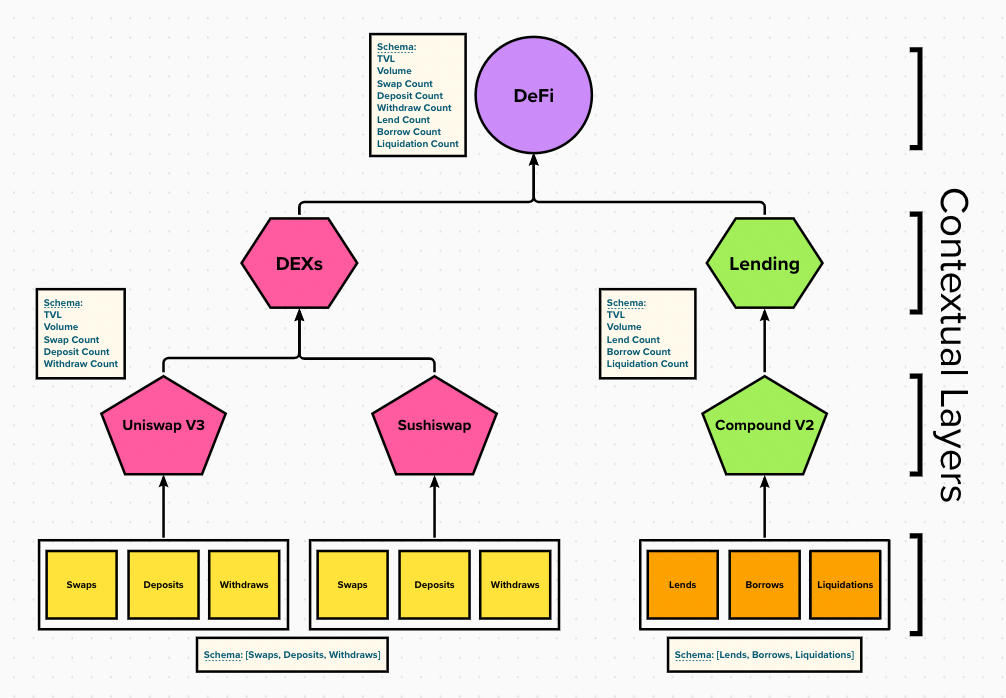
Step 1 - Define Context and Schema:
- The context and schema define the scope of data.
- For Messari subgraphs, the context is usually a single protocol. Still, it could be all protocols of a particular type, all activity on a specific blockchain, or various blockchains.
- Uniswap V3, Sushiswap, Curve Finance, and Balancer V2 are different contexts but share the same DEX (Decentralized Exchange) schema.
- The schema determines the data extracted from the context.
- The schema standardizes data extracted across different contexts.
- The context and schema can be composable and interconnected.
- Data within the same or different contextual layers may or may not have the same schema.
- Lower-level contexts may build context(s) in layers above.
- They may also be interweaving.
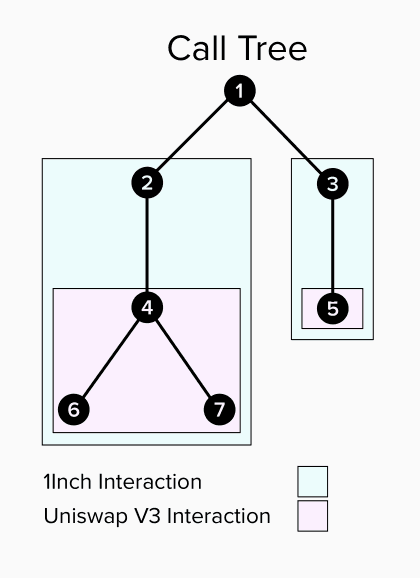
- Example: 1Inch executes transactions using liquidity pools on Uniswap V3.
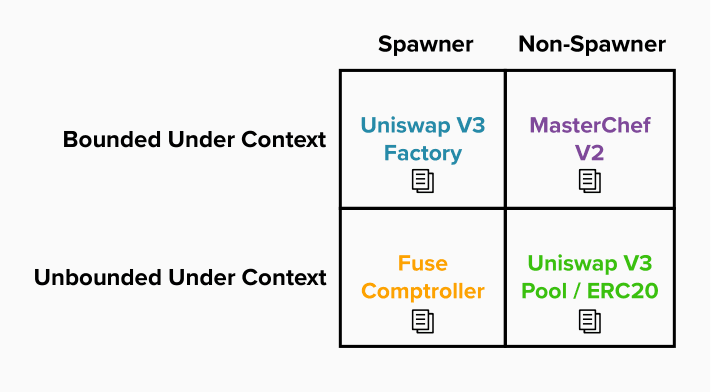
Step 2 - Identify Data Sources:
- Identify smart contracts with their
event logsandcall dataneeded under the context(s) to fulfill the schema. - Data Source Types:
- Spawner Data Source:
- These are contracts that are used to instantiate other contracts within a context.
- Examples:
Factory,Comptrollercontracts.
- Bounded Under Context Data Source.
- Data sources that have a bounded quantity under some context.
- Most often deployed directly by EOA (Externally Owned Account).
- The addresses of these data sources need to be identified before indexing.
- Examples:
Factory,Controller,MasterChefcontracts.
- Unbounded Under Context Data Source.
- Data sources can have any number of instantiations of the same contract under some context.
- Other contracts usually create them.
- These data sources can often be found by parsing
event logsorcall dataof spawner contracts. - Sometimes, however, they are directly deployed by EOAs.
- These can be difficult to track as an ad hoc data source.
- Requires staying up to date with the development of a protocol.
- These can be difficult to track as an ad hoc data source.
- These data sources can often be found by parsing
- Examples:
ERC20,UniswapV3Pool,Gaugecontracts.
- Other contracts usually create them.
- Data sources can have any number of instantiations of the same contract under some context.
- Spawner Data Source:
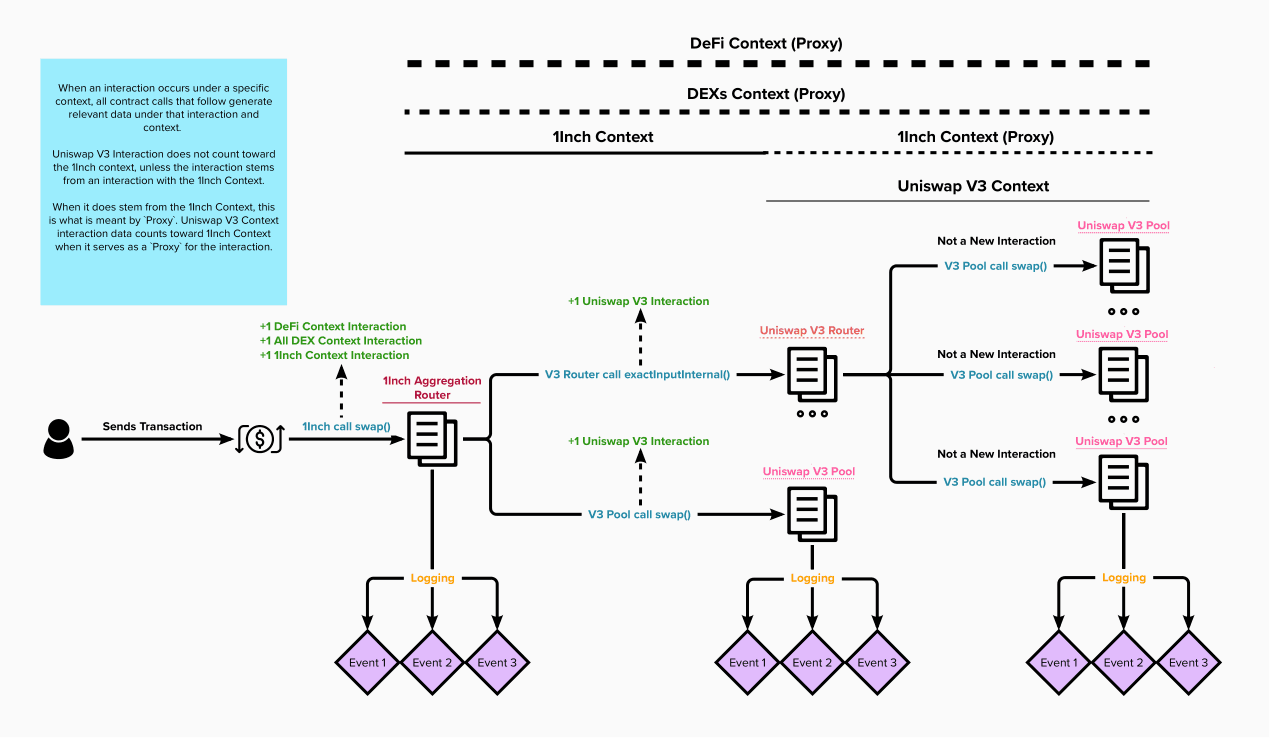
Step 3 - Identify Interactions:
- What is an interaction?
- An interaction is composed of transaction data and a connected tree of event logs and call data from an outside-of-context call to another context (See below for a visual explanation).
- Since there may be layered contexts, there may be layered interactions.
- The same call data or event logs can be contained in multiple interactions.
- Since there may be layered contexts, there may be layered interactions.
- Examples:
- A direct call from the user to the exactInputInternal() (executes a swap through a router) on the UniswapV3Router contract.
- An internal transaction call from the 1InchAggregationRouter to exactInputInternal() on the UniswapV3Router.
- Interaction with two contexts.
- +1 1Inch.
- +1 Uniswap V3.
- Interaction with two contexts.
- An interaction is composed of transaction data and a connected tree of event logs and call data from an outside-of-context call to another context (See below for a visual explanation).
- Why should we break down transactions into interactions?
- To understand the story of a transaction.
- Story: A larger tree that contains all interactions under all relevant contexts.
- To understand the story of a transaction.
- Multiple interactions.
- MultiCall.
- Aggregators.
- Protocols that route through or utilize other protocols.
- A user executing a swap on 1Inch using the 1InchAggregationRouter might execute a swap on Uniswap V3 that swaps on 2 UniswapV3Pool contracts (liquidity pools).
- This would result in 1 interaction with 1Inch, and 1 or 2 interactions with Uniswap V3.
- Note!!!:
- 1 Uniswap V3 interaction if 1InchAggregationRouter calls the UniswapV3Router which then calls the UniswapV3Pool contracts.
- 2 Uniswap V3 interactions if 1InchAggregationRouter calls the UniswapV3Pool contracts directly.
- Note!!!:
- This would result in 1 interaction with 1Inch, and 1 or 2 interactions with Uniswap V3.
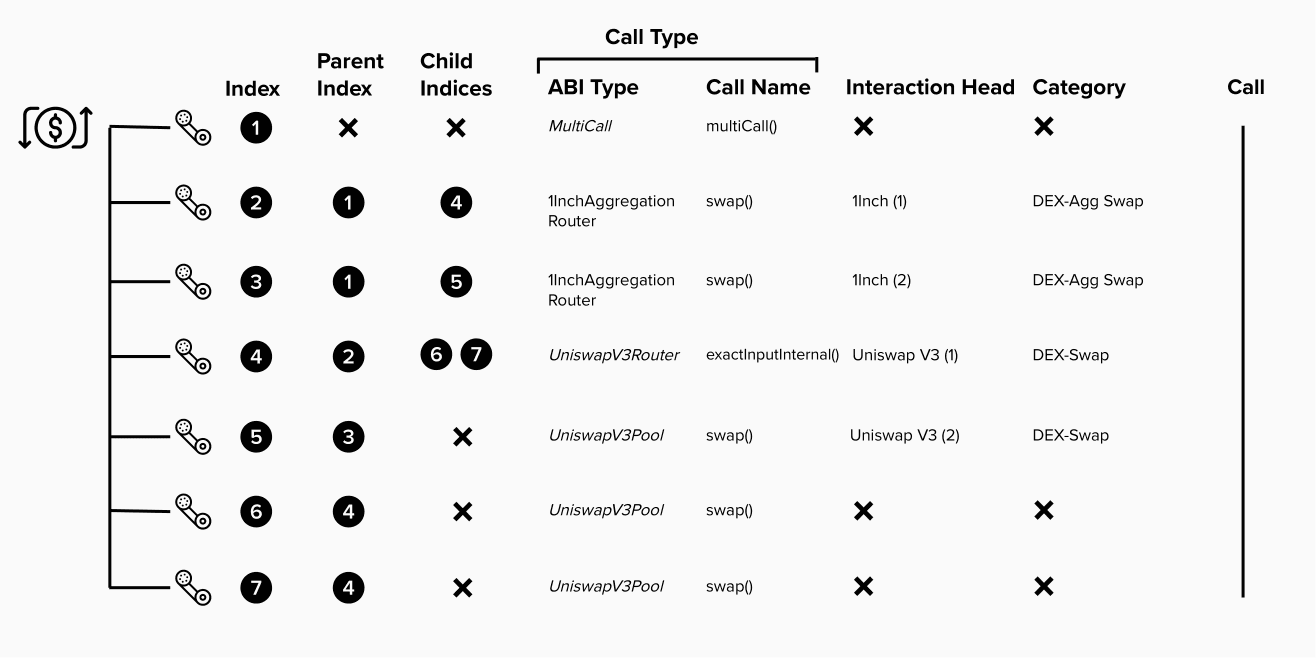
- Piecing together the story using:
Event logs.- Benefit:
- Faster.
- Less irrelevant data.
- Detriment:
- It may be tough, hacky, or impossible to piece the story together since it needs more contextual data about how contracts were called.
- Benefit:
Call data.- Benefit:
- Easy to build to the story since the call history gives a complete and connected contextual representation of the transaction.
- Have easy access to the call data.
- Detriment:
- Slower.
- More work is needed to understand the relationship between contract calls and their event logs and call data.
- Benefit:
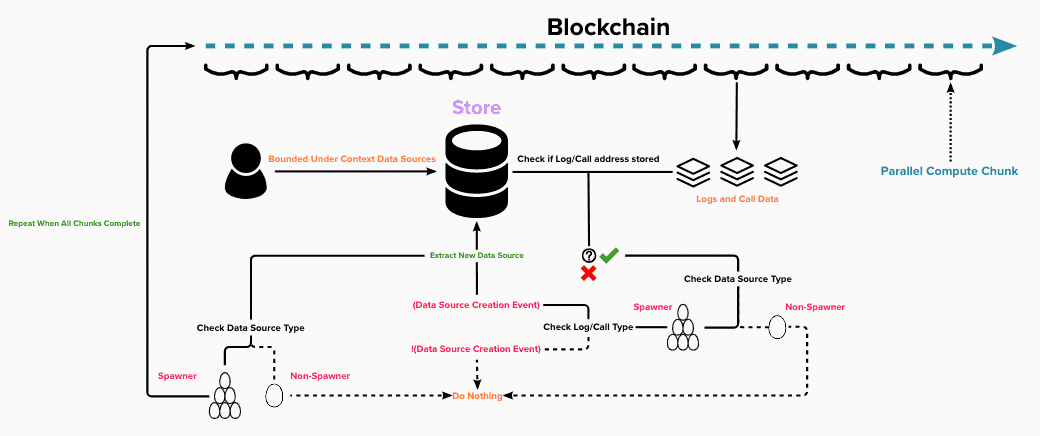
Step 4 - Store Data Sources:
- Process the blockchain for data sources and store all data source addresses.
- All data sources that do not have a spawner need to be specified before indexing.
- Note: There are some instances where a spawner commonly instantiates a contract of some type, but for one reason or another, there is an exception. These instances need to be specified as well.
- All additional data sources can be extracted by monitoring
call dataandevent logsfrom spawner contracts.- Usually, this can be accomplished with one parallel sweep of the blockchain. However, if it is the case that there is a spawner that can spawn another spawner, the blockchain may need to be processed multiple times.
- If there are instances where a spawner can spawn a contract of its type, a recursive process is necessary to extract all data sources reliably.
- Data sources extracted from the spawner contracts may be cached and used in later executions of the substream. This way, only the blocks since the most recent execution of the substream will need to be processed to extract any new data sources.
- Usually, this can be accomplished with one parallel sweep of the blockchain. However, if it is the case that there is a spawner that can spawn another spawner, the blockchain may need to be processed multiple times.
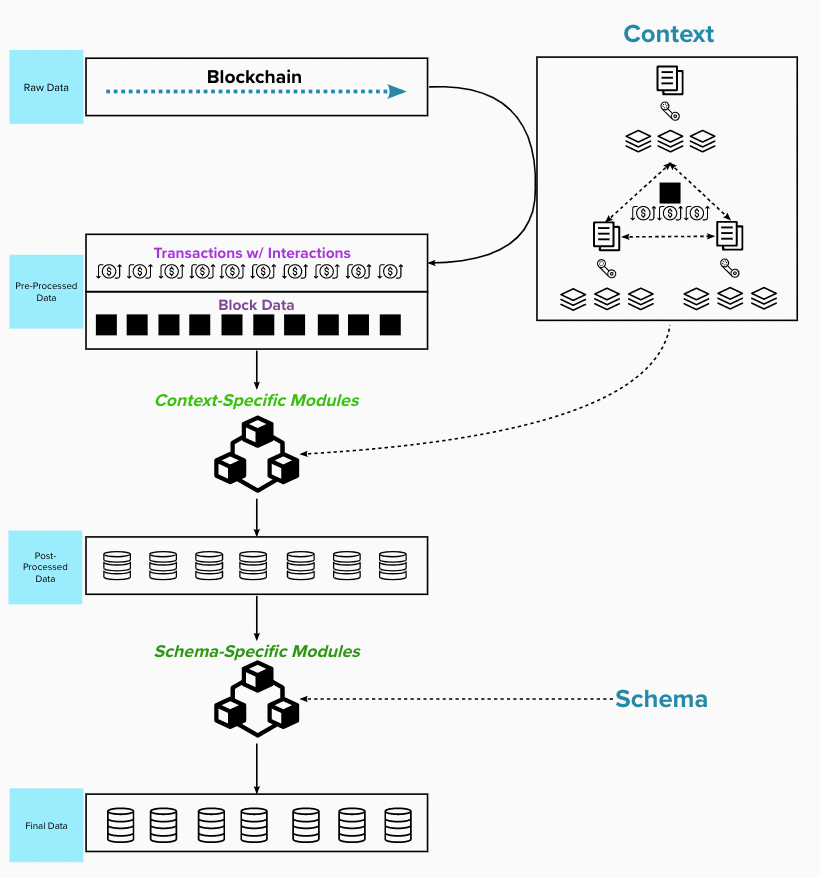
Step 5 - Pre-processing:
- Identify Relevant Transactions:
- Process the
call dataandevent logs.- Store transaction if one of the addresses matches a data source.
- Process the
- Parse Transaction Interactions:
- As specified in Step 3.
- Store interactions with transaction data.
- Prune Transactions:
- Prune event logs and call data that were not a part of any interactions above or are irrelevant.
- Augment Transaction/Interaction Data:
- Add any additional data that might help decode and handle the transaction in the next stage.
Step 6 - Transformation:
- Raw Data
- Raw Blockchain Data
- Pre-Processed Data
- Starting point for any new substream after preprocessing in the above step, and prepared for context-specific modules.
- Post-Processed Data
- Data after it has been transformed into a ready state to be passed into generic, schema-specific modules.
- Final Data
- The output of generic (schema-specific) modules for mapping post-processed data into final data (production/data applications input).
Pre-processed data are passed into context-specific modules.
- Context-specific modules:
- Unique to the context.
- Produce standard input for schema-specific modules.
- Map pre-processed data into post-processed data.
Post-processed data are passed into schema-specific modules.
- Schema-specific modules:
- Unique to the schema.
- Require standard input from the context-specific modules.
- Map post-processed data into final data.
Why start post-processing at the level of individual transactions?
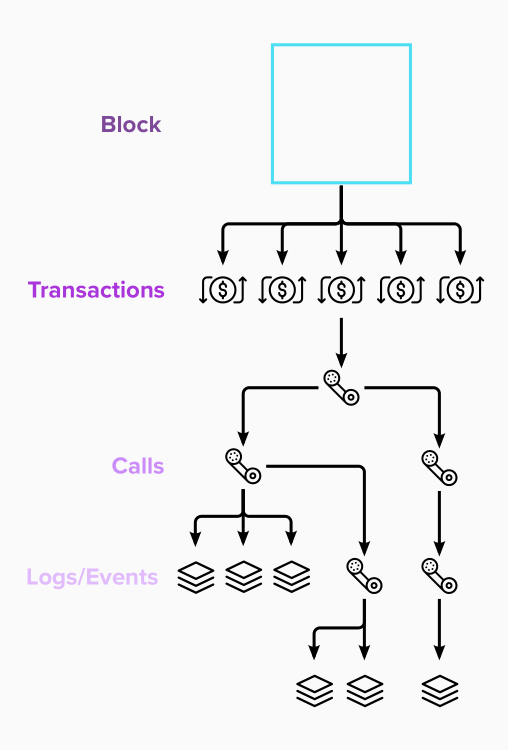
- Every transaction is initiated by an EOA (transaction.from).
- It is the fundamental unit of interaction with a blockchain, and almost all, if not all, relevant changes follow depending on the context and schema.
- Multiple events and call data are generated in a single transaction. This keeps them grouped as a single interaction.
- These can be parsed into multiple interactions at different context levels, which offers a path to mapping data at various levels of context with their schemas.
Opportunities for code generation and automation in the mapping process:
- Steps 1-3 could be facilitated through a CLI tool or specified in the configuration.
- Steps 4-5 could be done with reusable modules configured from the above steps.
- Step 6 - Module Standardization And Reusability:
- context-specific modules
- It may be shared across contextual layers.
- Example:
- Counting swaps on all DEXs will be a composite of swap counts in lower contextual layers [e.g. (Uniswap V3.swap_count) + (Sushiswap.swap_count)].
- Example:
- It may also be shared for contexts with similar or the same contract structures (call data and event logs).
- Example:
- Uniswap V3 and Sushiswap use the same UniswapV3Factory, UniswapV3Router, and UniswapV3Pool contract templates for facilitating DEX functionality.
- Example:
- It may be shared across contextual layers.
- Schema-specific modules:
- They are highly standardized and reusable since they require standard inputs, and there will be far fewer schemas than contexts since their goal is to standardize data across contexts.
- context-specific modules
- The necessary standard modules or
.spkgscan be placed in thesubstreams.yamlfor mapping Pre-Processed Data to Final Data based on the context and schema. - The novelty of any particular substream is in how we go from Pre-Processed Data to Post-Processed Data.
Where is developer discretion necessary/most important?
- Identifying context, interactions, and data sources.
- What data abstractions to work with or create after Step 5 between Pre-Processed and Post-Processed data?
- How to get from A to B?
- What are easy-to-use and efficient formats for a particular substream?
- Do we always atomize the transaction messages into event, call, or interaction messages?
- Do we need to process the Pre-Processed data more before moving toward Post-Processed data?
- What should the Post-Processed data look like, and how do we map from Post-Processed data into Final Data?
Come work with us!
If you’re a software engineer interested in helping us contextualize and categorize the world’s crypto data, we’re hiring. Check out our open engineering positions to find out more.